【动机】
在一些字符串的控制台对齐(例如居中对齐, 右对齐)输出的场景, 先决条件是计算其中每个字符的占宽(即在控制台中占几列), 以及控制台的总列数, 后者可以通过 tput cols 得到, 前者如果按 ${#str} 简单处理:
motive(){
local strs=("hello,world" "中文")
for str in ${strs[@]}; do
echo "length of <$str> is ${#str}"
done
}
motive输出:
length of <hello,world> is 11
length of <中文> is 2可以看到, ${#str} 获取的仅仅是字符串的字符总数, 而不是字符串在控制台占据的列数, 以此结果来作为字符串控制台对齐的基础, 纯粹的英文字母, 标点构成的字符串当然没问题, 但对于其他情况(例如例子中包含中文)显然是不严谨的.
如何识别这些占列数超过 1 的字符呢?
【意图】
以正则表达式的形式, 列举所有占列数为 1 的字符, 其余不匹配该正则表达式的字符占列数我们就认为是 2 (一些表情符号占列数可能为 3 或者更大, 本文暂不考虑)
【实现】
创建文件 system.sh, 写入函数 reg_one_span_chars
:<<COMMENT
屏幕占列数为 1 的字符的正则表达式
说明:
1. 简单枚举所有只占一列的字符
2. 该列表还应继续补充, 只需要在中间添加 echo -n "]" 前添加更多的 echo -n "..."即可
COMMENT
reg_one_span_chars(){
echo -n "["
echo -n " -~" #空格键到波浪线, 包括了键盘上的所有可见字符, 除了删除键以外
echo -n "αβγδεζηθικλμνξοπρστυφχψω" # 希腊字母
echo -n "♀🖐"
echo -n "]"
}作为示例, 其中包含了一些占列数为 1 的希腊字母和表情符号, 根据需要还可以添加.
新建 data.sh , 写入函数 cols_in_screen, 用于计算给定字符串的总占列数:
:<<COMMENT
获取字符串在屏幕上占据的列数.
$@: str 字符串
说明: 基本上可以兼容99.9% 的常见字符(中国境内), 必要时可以到
system.sh/reg_one_span_chars 函数中添加屏幕占列为 1 的字符集
COMMENT
cols_in_screen(){
local str="$@"
local char span total=0
for (( i=0; i<${#str}; i++ )); do
span=2
char=${str:$i:1}
[[ $char =~ $(reg_one_span_chars) ]] && span=1
let total+=span
done
echo $total
}【测试】
新建 test.sh
# 根据实际文件位置修改路径
source ./system.sh
source ./data.sh
way1(){
local strs=("hello,world"
"中文"
"hello,中文,end"
"希腊字母αβγδεζηθι"
"表情符号♀🖐👌"
$'\t试试转义字符\b\n'
)
for str in "${strs[@]}"; do
echo "<$str>: length is ${#str}, column amount is $(cols_in_screen $str)"
done
}
way1结果如下:
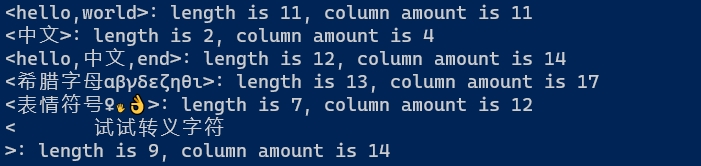
可以看到, 同样是表情符号, 占列数也可能不同. 如果非要考虑占据 3 列及以上的字符, 可能需要添加 reg_three_span_chars 之类的函数, 并重写 cols_in_screen 函数. 本文算是抛砖引玉吧.
同时, 注意到函数并未考虑转义字符. 因为 ocls_in_screen 函数主要是为了下一节的控制台对齐输出, 而大部分转义字符其实已经破坏了对齐, 所以我们认为, 继续深究是无意义的.